
Evidence for Template Theory
Of the four major theories of expertise, template theory appears to have the best fit with chess-derived empirical data. This view is supported by experiments.
As template theory is similar to chunking theory, it should be explained why the former is superior to the latter. One assumption of chunking is that the time interval in which a position is presented is too short for long-term memory (LTM) encoding. This restriction favored a system in which labels in short-term memory (STM) point to chunks in LTM. The problem is that several experiments have actually shown that LTM encoding does in fact happen during this period (Gobet & Simon, 1996). Templates, with unchanging cores and variable slots, form a larger, more complex retrieval structure and therefore account for these findings (Gobet & Jackson, 2002).
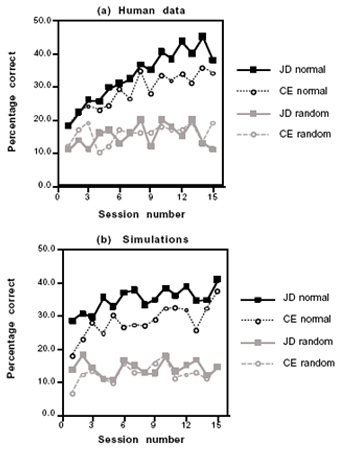
A graph of human data shows increasing accuracy on normal positions and consistent accuracy on random positions. A graph of computer-simulated data is very similar, suggesting the validity of the template theory.
(Gobet & Jackson, 2002)
Chess Novices
If a theory of expertise is actually true, it should apply to early learning as well as well-developed expertise. For this reason, the study of two chess novices by Gobet and Jackson (2002) is of particular interest.
In the experiment, 2 female undergraduate students with no knowledge of the rules or exposure to chess were subjected to a training phase and a testing phase. In training, the subjects were presented with 20 positions for 90 seconds each. 12 of the 20 were random positions from a database, and the remaining 8 were pairs of game positions selected from 4 "families" of positions. These 8 were to induce the development of templates.
In the testing phase, subjects were once again presented with 20 positions. 4 were taken from the training phase (2 from the game and 2 from "families"). A new position was taken from each of the 4 families used in training. A new position from each of 4 new families was also presented. Finally, there were 4 random positions. The order of presentation was randomized and controlled for systematic effects. Each position was presented for 5 seconds, and subjects had to recall the position in its entirety.
As one would predict, the subjects got more accurate with a greater number of trials, providing evidence for the development of expertise. The change in accuracy was regressed using a power function. The shape of the function is in line with the predictions made by template theory. Furthermore, a simulation of this experiment was performed using CHREST, a computer program used to study Chunk Hierarchy and REtrieval Structures. The computer used the concept of template theory to simulate the experiment, and the results were very similar to those of the human study, providing even more evidence for the applicability of template theory to chess expertise.

All Rights Reserved